模型性能评估
为什么要评估?
评估使路由变得数据驱动。通过测量 MMLU-Pro 上的每类别准确率(并使用 ARC 进行快速健全性检查),您可以:
- 为每个决策选择正确的模型并在 decisions.modelRefs 中配置它们
- 根据整体性能选择合理的 default_model
- 决定 CoT 提示是否值得延迟/成本权衡
- 在模型、提示词或参数更改时捕获回归
- 保持更改可复现和可审计,用于 CI 和发布
简而言之,评估将轶事转化为可测量的信号,从而提高路由器的质量、成本效率和可靠性。
本指南记录了通过 vLLM 兼容的 OpenAI 端点评估模型(MMLU-Pro 和 ARC Challenge)、生成基于性能的路由配置以及更新配置中 categories.model_scores 的自动化工作流程。
端到端运行内容
1) 评估模型
- 每类别准确率
- ARC Challenge:整体准确率
2) 可视化结果
- 每类别准确率的柱状图/热力图
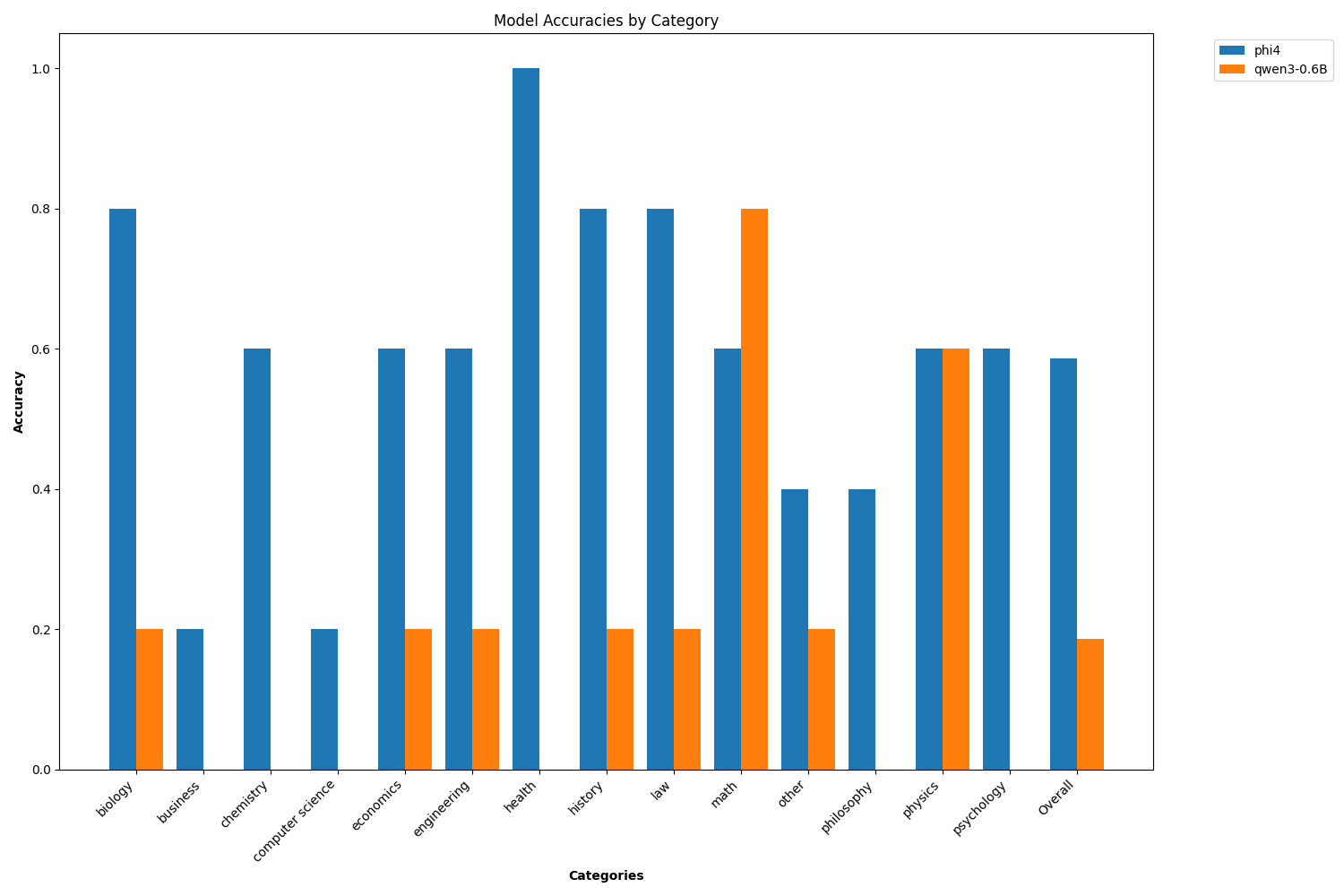
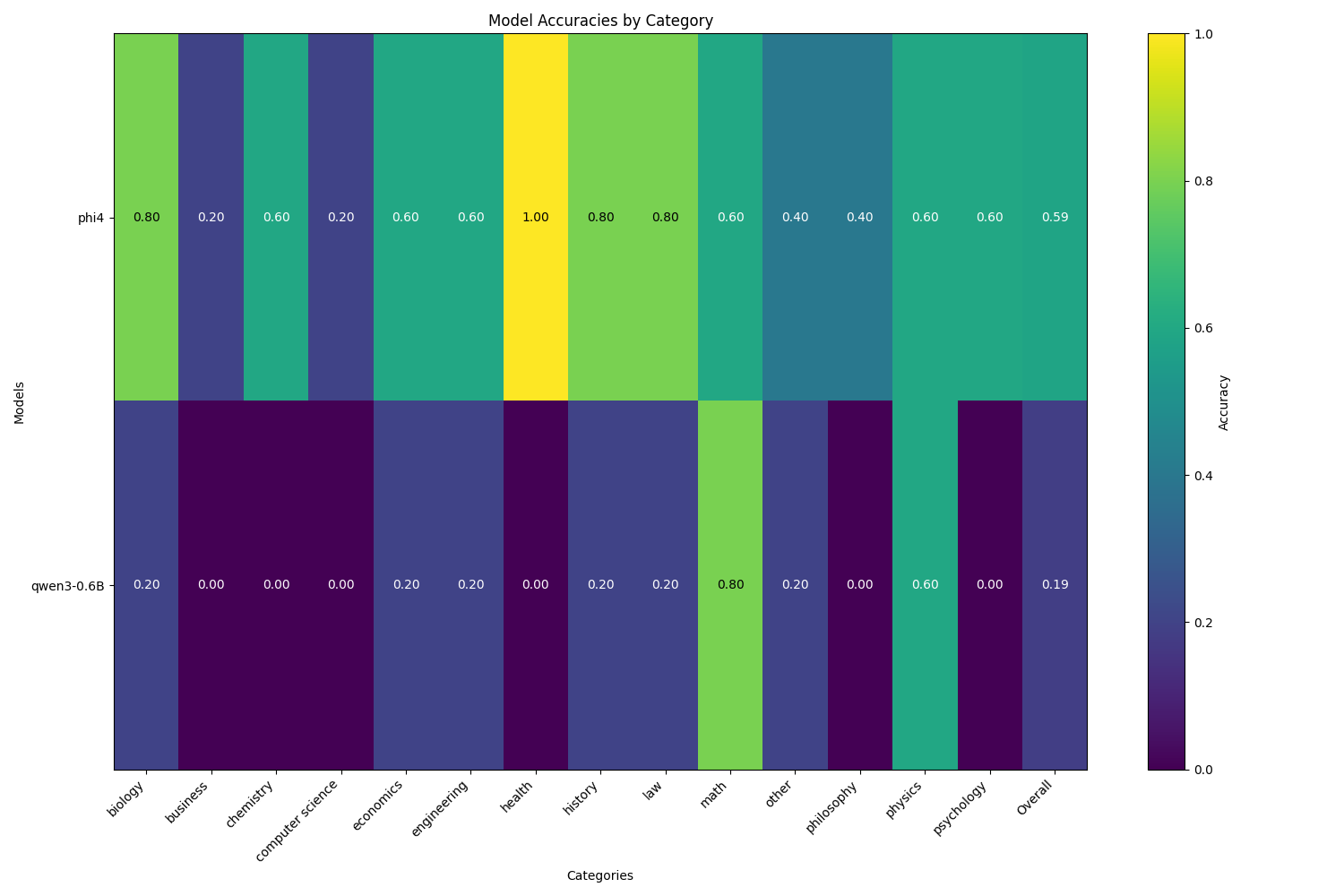
3) 生成更新的 config.yaml
- 为每个类别创建带有 modelRefs 的决策
- 将 default_model 设置为最佳平均表现者
- 保留或应用决策级推理设置
1.前置条件
-
运行中的 vLLM 兼容 OpenAI 端点,服务您的模型
- 端点 URL 如 http://localhost:8000/v1
- 如果端点需要,可选提供 API 密钥
# 终端 1
vllm serve microsoft/phi-4 --port 11434 --served_model_name phi4
# 终端 2
vllm serve Qwen/Qwen3-0.6B --port 11435 --served_model_name qwen3-0.6B -
评估脚本的 Python 包:
- 从仓库根目录:requirements.txt 中的 matplotlib
- 从
/src/training/model_eval:requirements.txt
# 本指南中我们将在此目录工作
cd /src/training/model_eval
pip install -r requirements.txt
⚠️ 关键配置要求:
vLLM 命令中的 --served-model-name 参数必须与 config/config.yaml 中的模型名称完全匹配:
# config/config.yaml 必须匹配上面的 --served-model-name 值
vllm_endpoints:
- name: "endpoint1"
address: "127.0.0.1"
port: 11434
- name: "endpoint2"
address: "127.0.0.1"
port: 11435
model_config:
"phi4": # ✅ 匹配 --served_model_name phi4
# ... 配置
"qwen3-0.6B": # ✅ 匹配 --served_model_name qwen3-0.6B
# ... 配置
可选提示:
- 确保您的
config/config.yaml包含vllm_endpoints[].models下的部署模型名称,以及model_config下的任何定价/策略,如果您计划直接使用生成的配置。
2.在 MMLU-Pro 上评估
示例使用模式
# 评估几个模型,每个类别少量样本,直接提示
python mmlu_pro_vllm_eval.py \
--endpoint http://localhost:11434/v1 \
--models phi4 \
--samples-per-category 10
python mmlu_pro_vllm_eval.py \
--endpoint http://localhost:11435/v1 \
--models qwen3-0.6B \
--samples-per-category 10
# 使用 CoT 评估(结果保存在 *_cot 下)
python mmlu_pro_vllm_eval.py \
--endpoint http://localhost:11435/v1 \
--models qwen3-0.6B \
--samples-per-category 10
--use-cot
# 如果您已正确设置语义路由,可以一次性运行
python mmlu_pro_vllm_eval.py \
--endpoint http://localhost:8801/v1 \
--models qwen3-0.6B, phi4 \
--samples-per-category
# --use-cot # 如果使用 CoT 取消此行注释
关键参数
- --endpoint:vLLM OpenAI URL(默认 http://localhost:8000/v1)
- --models:空格分隔的列表或单个逗号分隔的字符串;如果省略,脚本从端点查询 /models
- --categories:将评估限制在特定类别;如果省略,使用数据集中的所有类别
- --samples-per-category:限制每个类别的问题数(对快速运行有用)
- --use-cot:启用思维链提示变体;结果保存在单独的后缀子文件夹中(_cot vs_direct)
- --concurrent-requests:吞吐量并发数
- --output-dir:结果保存位置(默认 results)
- --max-tokens、--temperature、--seed:生成和可重复性参数
每个模型的输出
- results/Model_Name_(direct|cot)/
- detailed_results.csv:每个问题一行,包含 is_correct 和 category
- analysis.json:overall_accuracy、category_accuracy 映射、avg_response_time、counts
- summary.json:精简指标
- mmlu_pro_vllm_eval.txt:提示词和答案日志(调试/检查)
注意
- 模型命名:斜杠被替换为下划线作为文件夹名称;例如,gemma3:27b -> gemma3:27b_direct 目录。
- 类别准确率仅在成功查询上计算;失败请求被排除。
3.在 ARC Challenge 上评估(可选,整体健全性检查)
参见脚本:arc_challenge_vllm_eval.py
示例使用模式
python arc_challenge_vllm_eval.py \
--endpoint http://localhost:8801/v1\
--models qwen3-0.6B,phi4
--output-dir arc_results
关键参数
- --samples:要采样的总问题数(默认 20);在我们的脚本中 ARC 不按类别分类
- 其他参数与 MMLU-Pro 脚本一致
每个模型的输出
- results/Model_Name_(direct|cot)/
- detailed_results.csv:每个问题一行,包含 is_correct 和 category
- analysis.json:overall_accuracy、avg_response_time
- summary.json:精简指标
- arc_challenge_vllm_eval.txt:提示词和答案日志(调试/检查)
注意
- ARC 结果不直接用于
categories[].model_scores,但可以帮助发现回归。
4.可视化每类别性能
参见脚本:plot_category_accuracies.py
示例使用模式
# 使用 results/ 生成柱状图
python plot_category_accuracies.py \
--results-dir results \
--plot-type bar \
--output-file results/bar.png
# 使用 results/ 生成热力图
python plot_category_accuracies.py \
--results-dir results \
--plot-type heatmap \
--output-file results/heatmap.png
# 使用示例数据生成示例图
python src/training/model_eval/plot_category_accuracies.py \
--sample-data \
--plot-type heatmap \
--output-file results/category_accuracies.png
关键参数
- --results-dir:analysis.json 文件所在位置
- --plot-type:bar 或 heatmap
- --output-file:输出图像路径(默认 model_eval/category_accuracies.png)
- --sample-data:如果没有结果,生成假数据以预览图表
功能说明
- 查找所有
results/**/analysis.json,聚合每个模型的 analysis["category_accuracy"] - 添加一个 Overall 列表示跨类别的平均值
- 生成图表以快速比较模型/类别性能
注意
- 它通过在标签后附加
:direct或:cot将direct和cot合并为不同的模型变体;图例为简洁起见隐藏:direct。
5.生成基于性能的路由配置
参见脚本:result_to_config.py
示例使用模式
# 使用 results/ 生成新配置文件(不覆盖)
python src/training/model_eval/result_to_config.py \
--results-dir results \
--output-file config/config.eval.yaml
# 修改相似度阈值
python src/training/model_eval/result_to_config.py \
--results-dir results \
--output-file config/config.eval.yaml \
--similarity-threshold 0.85
# 从特定文件夹生成
python src/training/model_eval/result_to_config.py \
--results-dir results/mmlu_run_2025_09_10 \
--output-file config/config.eval.yaml
关键参数
- --results-dir:指向 analysis.json 文件所在的文件夹
- --output-file:目标配置路径(默认 config/config.yaml)
- --similarity-threshold:在生成的配置中设置的语义缓存阈值
功能说明
- 读取所有
analysis.json文件,提取 analysis["category_accuracy"] - 构建新配置:
- categories:创建简化的类别定义(仅名称)
- decisions:对于结果中存在的每个类别,创建一个决策,包含:
- rules:基于领域的路由条件
- modelRefs:按准确率排名的模型(无分数字段)
- plugins:系统提示词和其他配置
- default_model:跨类别的最佳平均表现者
- 决策推理设置:从内置映射自动填充(生成后可调整)
- math、physics、chemistry、CS、engineering -> 高推理
- 其他默认 -> 低/中
- 如果存在,排除任何特殊的 "auto" 占位符模型
Schema 对齐
- categories[].name:MMLU-Pro 类别字符串(简化,无 model_scores)
- decisions[].name:匹配类别名称
- decisions[].modelRefs:该类别按准确率排名的模型(无分数字段)
- decisions[].rules:基于领域的路由条件
- decisions[].plugins:system_prompt 和其他策略配置
- default_model:跨类别��的顶级表现者(移除方法后缀,例如 gemma3:27b 来自 gemma3:27b:direct)
- 保留其他配置部分(semantic_cache、tools、classifier、prompt_guard)使用合理默认值;如果您的环境不同,可以在生成后编辑它们
注意
- 此脚本仅适用于 MMLU_Pro 评估的结果。
- 现有 config.yaml 可能被覆盖。考虑先写入临时文件并进行 diff:
--output-file config/config.eval.yaml
- 如果您的生产 config.yaml 包含环境特定设置(端点、定价、策略),请将评估的
decisions[].modelRefs和default_model移植回您的规范配置。
示例 config.eval.yaml
参见更多配置信息:配置
bert_model:
model_id: sentence-transformers/all-MiniLM-L12-v2
threshold: 0.6
use_cpu: true
semantic_cache:
enabled: true
similarity_threshold: 0.85
max_entries: 1000
ttl_seconds: 3600
tools:
enabled: true
top_k: 3
similarity_threshold: 0.2
tools_db_path: config/tools_db.json
fallback_to_empty: true
prompt_guard:
enabled: true
use_modernbert: true
model_id: models/jailbreak_classifier_modernbert-base_model
threshold: 0.7
use_cpu: true
jailbreak_mapping_path: models/jailbreak_classifier_modernbert-base_model/jailbreak_type_mapping.json
# 这里缺少端点配置和 model_config,根据需要修改
classifier:
category_model:
model_id: models/category_classifier_modernbert-base_model
use_modernbert: true
threshold: 0.6
use_cpu: true
category_mapping_path: models/category_classifier_modernbert-base_model/category_mapping.json
pii_model:
model_id: models/pii_classifier_modernbert-base_presidio_token_model
use_modernbert: true
threshold: 0.7
use_cpu: true
pii_mapping_path: models/pii_classifier_modernbert-base_presidio_token_model/pii_type_mapping.json
categories:
- name: business
- name: law
- name: engineering
decisions:
- name: business
description: "Route business queries"
priority: 10
reasoning_effort: low
rules:
operator: "OR"
conditions:
- type: "domain"
name: "business"
modelRefs:
- model: phi4
use_reasoning: false
- model: qwen3-0.6B
use_reasoning: false
plugins:
- type: "system_prompt"
configuration:
enabled: true
system_prompt: "Business content is typically conversational"
mode: "replace"
- name: law
description: "Route legal queries"
priority: 10
reasoning_effort: medium
rules:
operator: "OR"
conditions:
- type: "domain"
name: "law"
modelRefs:
- model: phi4
use_reasoning: false
- model: qwen3-0.6B
use_reasoning: false
plugins:
- type: "system_prompt"
configuration:
enabled: true
system_prompt: "Legal content is typically explanatory"
mode: "replace"
# 此处省略一些类别
- name: engineering
description: "Route engineering queries"
priority: 10
reasoning_effort: high
rules:
operator: "OR"
conditions:
- type: "domain"
name: "engineering"
modelRefs:
- model: phi4
use_reasoning: true
- model: qwen3-0.6B
use_reasoning: true
plugins:
- type: "system_prompt"
configuration:
enabled: true
system_prompt: "Engineering problems require systematic problem-solving"
mode: "replace"
default_reasoning_effort: medium
default_model: phi4